浅析Vue中的domDiff
现代的前端框架,都引入了虚拟DOM的机制,这不可避免的涉及到从虚拟DOM和真实DOM的对比过程,寻找差异后更新到真实DOM树,完成视图的渲染。
diff算法是啥
diff,就是两颗结点树对比,寻找差异的逻辑处理过程,也就是(search DOM difference),平时也叫 DOM Diff。 因为在程序中数据状态改变了,驱动这虚拟DOM(VNode)变了,在更新到视图的过程中,如何将变化传递到视图层,以最小的代价来完成patch。

我们都知道浏览器渲染DOM的成本是比较高的,加载一个网页的时候,要经过解析、布局、渲染、绘制等诸多过程的。为了能减少损耗,这里的关键是,实现一个高效的比对策略,能用最小的成本,变更真实的DOM树。 减少对真实DOM树的操纵频次。
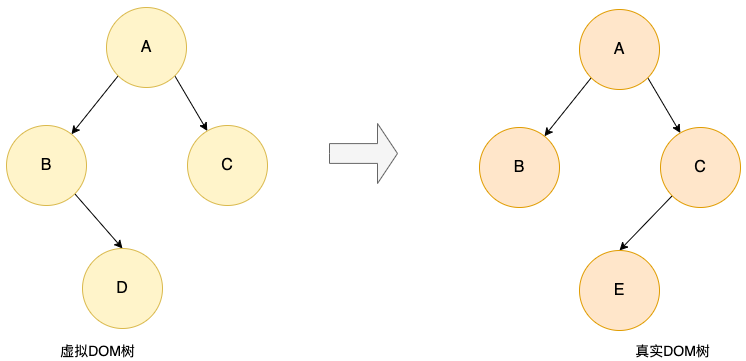
然而,两颗树的完全对比,需要O(n^3)的时间复杂度,这在页面中结点数量比较多的时候,是比较消耗性能的。 为此前端的主流框架Vue、React都是采用了一定的优化策略,将对比的DOM Diff的时间复杂度降低到了O(n)的时间复杂内。
完全对比为啥是O(n^3)的时间复杂度?每个结点和另一棵树的所有结点对比一遍,就是O(n^2)的时间消耗,再加每个结点的移动更新,这又是O(n)的时间消耗
- 舍弃了跨层的结点比较,只比较同级的结点
- 只处理同类型的结点,结点类型不同时,销毁重建
- 根据结点唯一标识key属性,尽量复用之前的结点
假如有这样的一段代码
<ul>
<li>A</li>
<li>B</li>
<li>C</li>
<li>D</li>
</ul><ul>
<li>A</li>
<li>B</li>
<li>C</li>
<li>D</li>
</ul>列表中的 li 标签是 ul 标签的子节点,我们可以使用下面的数组来表示 ul 标签的 children:
[
h('li', null, 'A'),
h('li', null, 'B'),
h('li', null, 'C'),
h('li', null, 'D')
][
h('li', null, 'A'),
h('li', null, 'B'),
h('li', null, 'C'),
h('li', null, 'D')
]假如数据发生了改变,需要删除其中的一个结点。
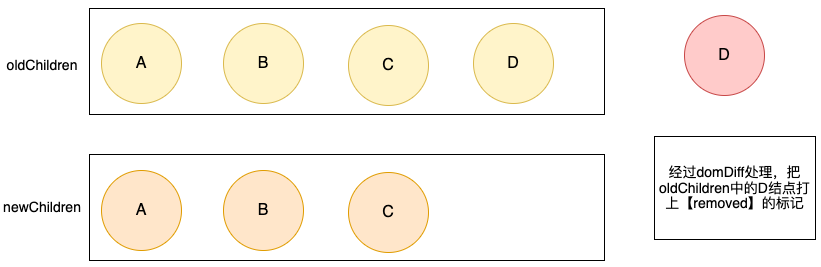
这里暂时把domDiff当成一个黑盒,我们给传入(newVNode, oldVNode),它就能找到差异,知道了要把D结点移除,其余的结点保持不变。在渲染器真正执行render的时候就把D结点删除,从而视图更新。
当数据发生改变,需要新增一条记录,对应增加一个VNode结点
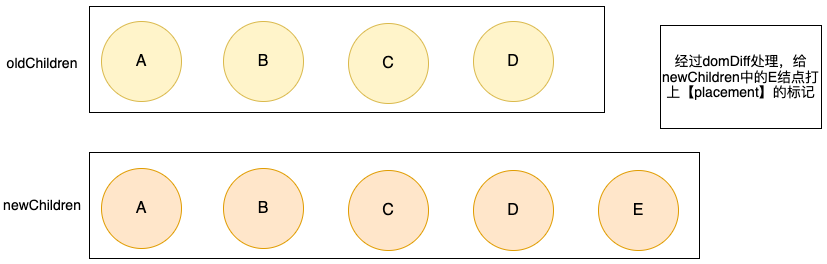
这里暂时把domDiff当成一个黑盒,我们给传入(newVNode, oldVNode),它就能找到差异,要新加一个E结点。
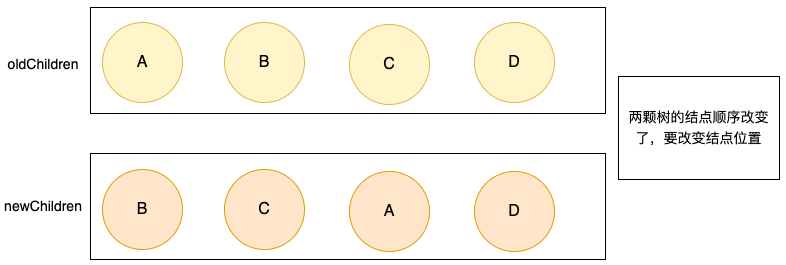
这是比较复杂的一种情况,两颗树上的结点只是位置发生了改变,domDiff如何处理的呢? vue2 和 vue3 采用了不同的算法处理策略,在react框架中有fiber的架构模式处理逻辑又不同的。
vue2.x中的双端比较
双端对比,就是分别从新旧children列表的起始和结束位置出发,向中间的位置靠拢,通过【新-旧】起始位置、【新-旧】结束位置、【新起始-旧结束】位置、【新结束-旧起始】位置四种模式交叉对比结点。
// 定义新children列表的起始 和 结束位置
let [newStartIdx, newEndIdx] = [0, newChildren.length - 1];
// 定义新children的 起始结点 和 结束结点
let [newStartVNode, newEndVNode] = [newChildren[newStartIdx], newChildren[newEndIdx]];
// 定义旧children列表的起始 和 结束位置
let [oldStartIdx, oldEndIdx] = [0, oldChildren.length - 1];
// 定义就children的 起始结点 和 结束结点
let [oldStartVNode, oldEndVNode] = [oldChildren[oldStartIdx], oldChildren[oldEndIdx]];// 定义新children列表的起始 和 结束位置
let [newStartIdx, newEndIdx] = [0, newChildren.length - 1];
// 定义新children的 起始结点 和 结束结点
let [newStartVNode, newEndVNode] = [newChildren[newStartIdx], newChildren[newEndIdx]];
// 定义旧children列表的起始 和 结束位置
let [oldStartIdx, oldEndIdx] = [0, oldChildren.length - 1];
// 定义就children的 起始结点 和 结束结点
let [oldStartVNode, oldEndVNode] = [oldChildren[oldStartIdx], oldChildren[oldEndIdx]];有了这些基础信息,我们就可以开始执行双端比较了,在一次比较过程中,最多需要进行四次比较:
- 使用旧 children 的头一个 VNode 与新 children 的头一个 VNode 比对,即 oldStartVNode 和 newStartVNode 比对。
- 使用旧 children 的最后一个 VNode 与新 children 的最后一个 VNode 比对,即 oldEndVNode 和 newEndVNode 比对。
- 使用旧 children 的头一个 VNode 与新 children 的最后一个 VNode 比对,即 oldStartVNode 和 newEndVNode 比对。
- 使用旧 children 的最后一个 VNode 与新 children 的头一个 VNode 比对,即 oldEndVNode 和 newStartVNode 比对。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 步骤一:oldStartVNode 和 newStartVNode 比对
} else if (oldEndVNode.key === newEndVNode.key) {
// 步骤二:oldEndVNode 和 newEndVNode 比对
} else if (oldStartVNode.key === newEndVNode.key) {
// 步骤三:oldStartVNode 和 newEndVNode 比对
} else if (oldEndVNode.key === newStartVNode.key) {
// 步骤四:oldEndVNode 和 newStartVNode 比对
}
}while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 步骤一:oldStartVNode 和 newStartVNode 比对
} else if (oldEndVNode.key === newEndVNode.key) {
// 步骤二:oldEndVNode 和 newEndVNode 比对
} else if (oldStartVNode.key === newEndVNode.key) {
// 步骤三:oldStartVNode 和 newEndVNode 比对
} else if (oldEndVNode.key === newStartVNode.key) {
// 步骤四:oldEndVNode 和 newStartVNode 比对
}
}还是拿这段模板举例,这时我们给每个标签加上key标识。
<ul>
<li key="a">A</li>
<li key="b">B</li>
<li key="c">C</li>
<li key="d">D</li>
</ul><ul>
<li key="a">A</li>
<li key="b">B</li>
<li key="c">C</li>
<li key="d">D</li>
</ul>开启双端比较的过程
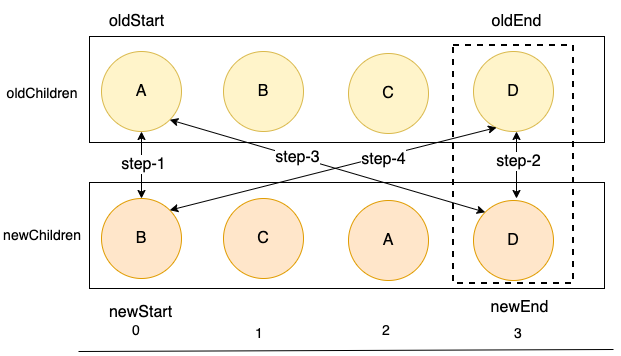
这轮的比较中,在步骤二,我们发现新旧子列表中的最后一个结点D相同,此时我们就可以移动新旧children列表的尾指针了。
else if (oldEndVNode.key === newEndVNode.key) {
// 步骤二:oldEndVNode 和 newEndVNode 比对
oldEndIdx--;
newEndIdx--;
}else if (oldEndVNode.key === newEndVNode.key) {
// 步骤二:oldEndVNode 和 newEndVNode 比对
oldEndIdx--;
newEndIdx--;
}此时,新旧children的尾指针分别向前移动了一位,newEndIdx = oldEndIdx = 3。接着开启下一轮的比较:
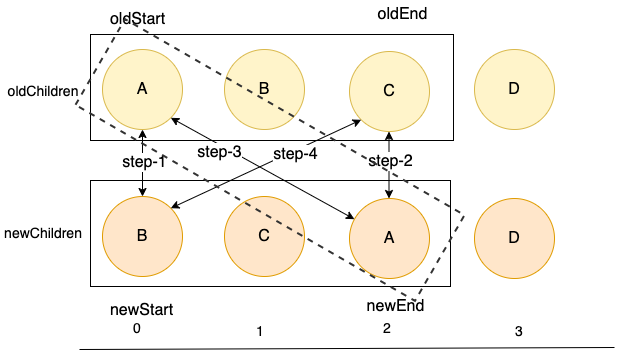
这轮的比较中,在步骤三,找到了可复用的结点A,走到了下面的 if 分支的处理逻辑中了。
else if (oldStartVNode.key === newEndVNode.key) {
// 步骤三:oldStartVNode 和 newEndVNode 比对
// 将 oldStartVNode.el 移动到 oldEndVNode.el 的后面,也就是 oldEndVNode.el.nextSibling 的前面
container.insertBefore(
oldStartVNode.el,
oldEndVNode.el.nextSibling
)
// 更新索引,指向下一个位置
oldStartVNode = oldChildren[++oldStartIdx]
newEndVNode = newChildren[--newEndIdx]
}else if (oldStartVNode.key === newEndVNode.key) {
// 步骤三:oldStartVNode 和 newEndVNode 比对
// 将 oldStartVNode.el 移动到 oldEndVNode.el 的后面,也就是 oldEndVNode.el.nextSibling 的前面
container.insertBefore(
oldStartVNode.el,
oldEndVNode.el.nextSibling
)
// 更新索引,指向下一个位置
oldStartVNode = oldChildren[++oldStartIdx]
newEndVNode = newChildren[--newEndIdx]
}此时,将旧的oldStartVNode移动到了 oldChildren 结尾位置,同时将 newEndIdx - 1,oldStartIdx + 1,表示将旧列表的起始指针向右移动一位,新列表的结束指针向左移动一位。接着开启下一轮的比较:
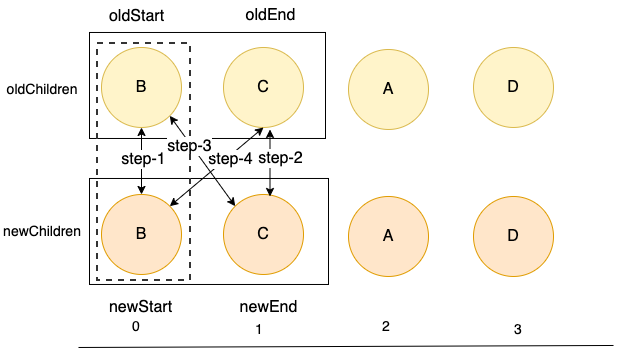
这轮的比较中,在步骤一,找到了可复用的结点结点B,走到下面的if 分支的处理逻辑中了。
if (oldStartVNode.key === newStartVNode.key) {
// 步骤一:oldStartVNode 和 newStartVNode 比对
newStartIdx++;
oldStartIdx++;
}if (oldStartVNode.key === newStartVNode.key) {
// 步骤一:oldStartVNode 和 newStartVNode 比对
newStartIdx++;
oldStartIdx++;
}此时,同时将 newStartIdx + 1,oldStartIdx + 1,表示将新、旧列表的起始指针向右移动一位。接着开启下一轮的比较:
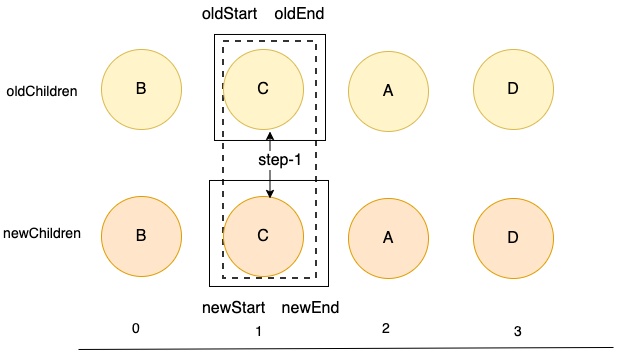
此时,比较直观的看到,新旧children都只剩最后一个结点C,且都是相同,可直接复用。这轮结束后,新老指针相遇,标志着diff的过程就结束了。 这也是比较理想的情况了,四轮的比较中,只移动了一次。
非理想的情况
假如遇到了下面的这种情况,在一轮的四次对比中,均没有找到可复用的结点呢?
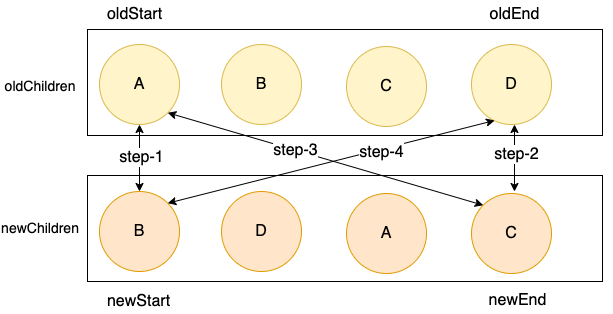
此时,①、②、③、④ 这四步中均没有找到可复用的结点,需要拿newChildren中的第一个结点,去到oldChildren中逐一去匹配了。在代码中就要增加一个 else的分支判断了。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 步骤一:oldStartVNode 和 newStartVNode 比对
} else if (oldEndVNode.key === newEndVNode.key) {
// 步骤二:oldEndVNode 和 newEndVNode 比对
} else if (oldStartVNode.key === newEndVNode.key) {
// 步骤三:oldStartVNode 和 newEndVNode 比对
} else if (oldEndVNode.key === newStartVNode.key) {
// 步骤四:oldEndVNode 和 newStartVNode 比对
} else {
// 上面👆🏻的四步均没有找到可以复用的结点,走到else分支中
// 遍历旧 children,试图寻找与 newStartVNode 拥有相同 key 值的元素
const idxInOld = oldChildren.findIndex(child => child.key === newStartVNode.key);
}
}while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVNode.key === newStartVNode.key) {
// 步骤一:oldStartVNode 和 newStartVNode 比对
} else if (oldEndVNode.key === newEndVNode.key) {
// 步骤二:oldEndVNode 和 newEndVNode 比对
} else if (oldStartVNode.key === newEndVNode.key) {
// 步骤三:oldStartVNode 和 newEndVNode 比对
} else if (oldEndVNode.key === newStartVNode.key) {
// 步骤四:oldEndVNode 和 newStartVNode 比对
} else {
// 上面👆🏻的四步均没有找到可以复用的结点,走到else分支中
// 遍历旧 children,试图寻找与 newStartVNode 拥有相同 key 值的元素
const idxInOld = oldChildren.findIndex(child => child.key === newStartVNode.key);
}
}在oldChildren 中的找到了第二个结点B,可以复用。
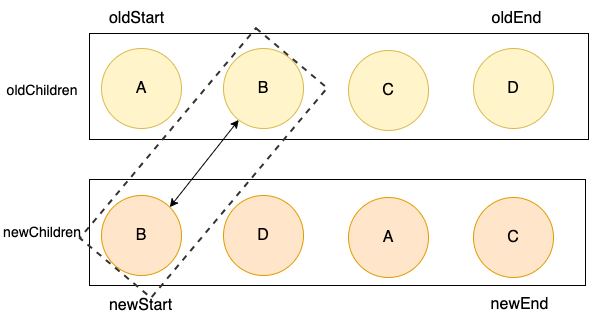
将其移动到旧列表的首位,并将原来的位置,设置成undefined。
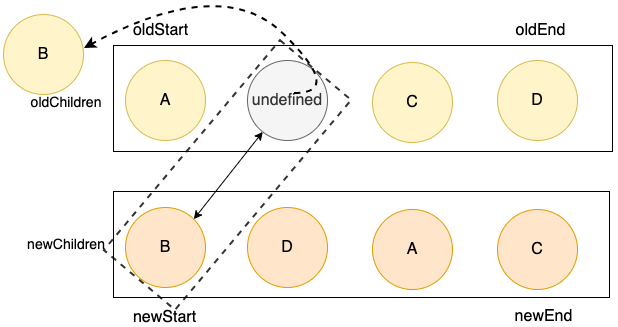
代码实现如下:
if (idxInOld >= 0) { // 匹配到了旧列表中的结点
const movedNode = oldChildren[idxInOld];
oldChildren[idxInOld] = undefined;
container.insertBefore(movedNode.el, oldStartVNode.el)
}
// 将新列表中的起始指针,向右移动一位
newStartVNode = newChildren[++newStartIdx]if (idxInOld >= 0) { // 匹配到了旧列表中的结点
const movedNode = oldChildren[idxInOld];
oldChildren[idxInOld] = undefined;
container.insertBefore(movedNode.el, oldStartVNode.el)
}
// 将新列表中的起始指针,向右移动一位
newStartVNode = newChildren[++newStartIdx]开启下一轮的查找过程
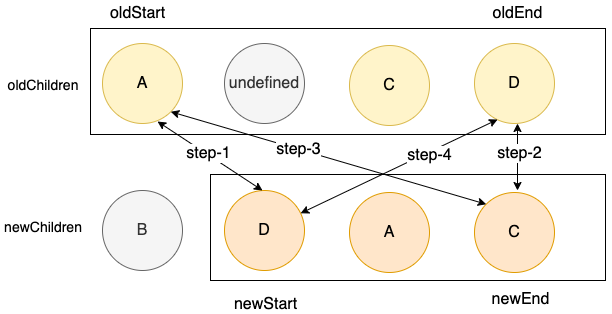
本轮结束后,出现了上图所示的情况,在步骤四种找到了可以用结点D
有个问题需要注意,第二位置,已经是undefined了,当oldStart 或着 oldEnd走到这里的时候,需要处理一下边界情况
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (!oldStartVNode) {
oldStartVNode = oldChildren[++oldStartIdx]
} else if (!oldEndVNode) {
oldEndVNode = oldChildren[--oldEndIdx]
}
// 省略......
}while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (!oldStartVNode) {
oldStartVNode = oldChildren[++oldStartIdx]
} else if (!oldEndVNode) {
oldEndVNode = oldChildren[--oldEndIdx]
}
// 省略......
}出现新结点
上面讨论的都是新旧列表结点树相同的情况,我们再来看新列表多出结点的情况
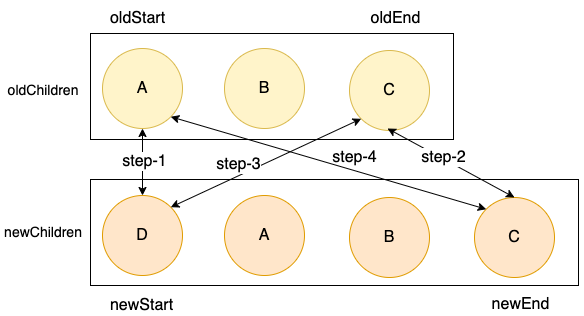
按照上面的逻辑处理,在步骤二中匹配成功,进入下一轮
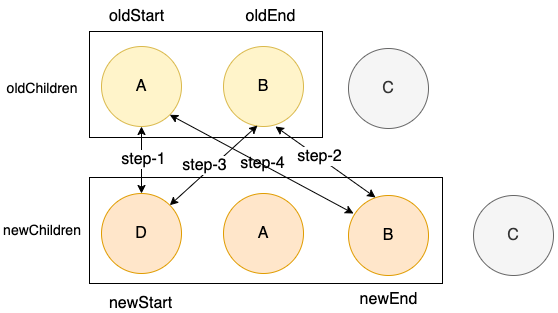
依然是在第二步中找到可复用结点,进入下一轮
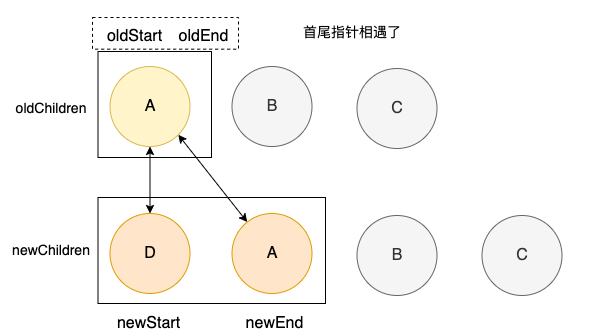
此时,旧列表中首尾指针相遇,表示着就剩下最后一个结点,而新列表中还有两个结点。找到可复用的结点A后出现下面的情况
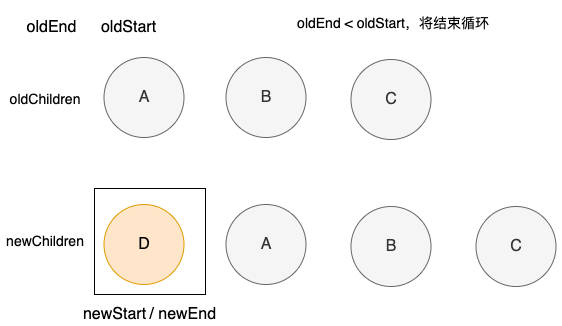
旧列表中的结点处理完成,新列表还剩一个结点D,且由于 (oldEnd < oldStart)触发了 oldStartIdx <= oldEndIdx不成立,循环终止。我们需要将新列表中剩余的结点,插入。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 省略...
}
if (oldEndIdx < oldStartIdx) {
// 添加 剩余的 新列表中的结点
for (let i = newStartIdx; i <= newEndIdx; i++) {
mount(newChildren[i], container, false, oldStartVNode.el)
}
}while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 省略...
}
if (oldEndIdx < oldStartIdx) {
// 添加 剩余的 新列表中的结点
for (let i = newStartIdx; i <= newEndIdx; i++) {
mount(newChildren[i], container, false, oldStartVNode.el)
}
}移除旧结点
再看旧列表中,有多余结点的情况
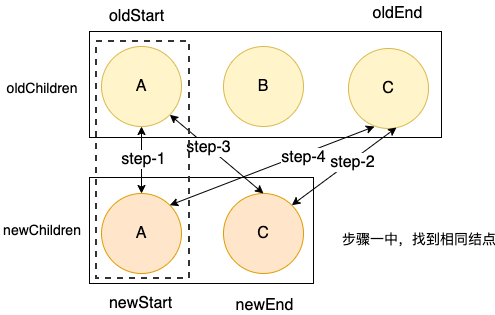
一轮结束后,在步骤一,找到相同的结点,开启下一轮
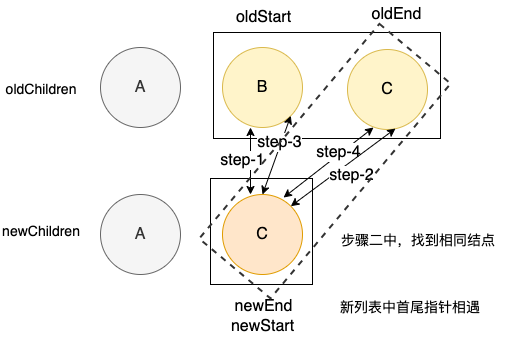
此时,新列表中的首尾指针相遇,并且找到了相同的结点C,在开启下一轮之前,
oldEndIdx++;
newEndIdx++oldEndIdx++;
newEndIdx++产生了下面的的情况,循环就不会再走下去了。
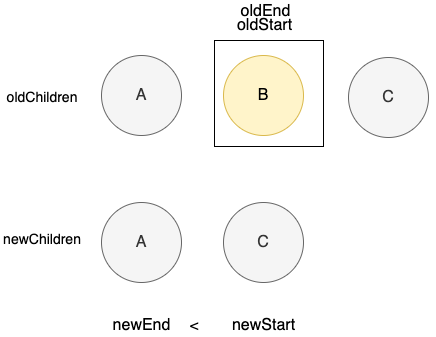
newEndIdx < newStartId,表示有旧列表中的元素要被移除了,添加下面的代码逻辑
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 双端指针向中间不断靠拢,比对的逻辑
}
// 双向的比较结束后
if (oldEndIdx < oldStartIdx) {
// 添加新节点 逻辑
} else if (newEndIdx < newStartIdx) {
// 需要移除旧列表中多余的结点
for (let i = oldStartIdx; i <= oldEndIdx; i++) {
container.removeChild(oldChildren[i].el)
}
}while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 双端指针向中间不断靠拢,比对的逻辑
}
// 双向的比较结束后
if (oldEndIdx < oldStartIdx) {
// 添加新节点 逻辑
} else if (newEndIdx < newStartIdx) {
// 需要移除旧列表中多余的结点
for (let i = oldStartIdx; i <= oldEndIdx; i++) {
container.removeChild(oldChildren[i].el)
}
}这样,将旧列表中[oldStart, oldEnd]之间的结点全部移除。以上就是vue2中双端比较的diff实现过程,其借鉴了开源库 snabbdom 的设计思想。
缺点
vue2.x中采用全量的Diff,当数据状态变更后,新生成一颗DOM树,并和之前的DOM树对比,找到不同的结点再更新,如果结点的数量较多,层级较深,会消耗大量的内存。
vue3.x 中的最长递增子序列
Vue3版本中采用了另外的一种diff比较算法,进行了Diff过程的优化。
- 静态标记 + 非全量diff,根据DOM内容以后是否发生变化,做静态标记,以后会跳过静态结点,提升对比效率
- 采用
最长递增子序列的算法方式,优化对比流程,最大程度地减少DOM结点的移动
核心的处理思路有两个:
- 列表的 前置处理 和 后置处理
- 最长递增子序列 对比方式
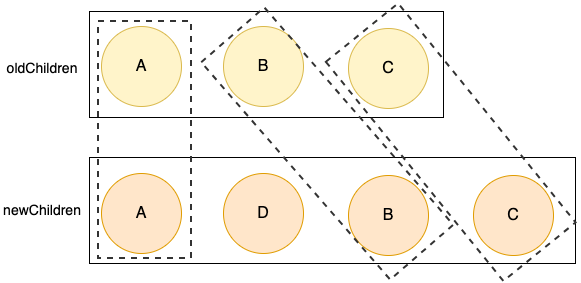
如上图所示,新旧列表中取出相同的前缀结点和后缀结点后,需要对比的结点就很少了,可以提升效率。 更新相同的前缀节点处理逻辑如下所示:
// j 为指向新旧 children 中第一个节点的索引
let j = 0
let oldVNode = oldChildren[j]
let newVNode = newChildren[j]
// while 循环向后遍历,直到遇到拥有不同 key 值的节点为止
while (oldVNode.key === newVNode.key) {
// 调用 patch 函数更新 ...
j++
oldVNode = oldChildren[j]
newVNode = newChildren[j]
}// j 为指向新旧 children 中第一个节点的索引
let j = 0
let oldVNode = oldChildren[j]
let newVNode = newChildren[j]
// while 循环向后遍历,直到遇到拥有不同 key 值的节点为止
while (oldVNode.key === newVNode.key) {
// 调用 patch 函数更新 ...
j++
oldVNode = oldChildren[j]
newVNode = newChildren[j]
}更新相同的后缀节点
// 指向旧 children 最后一个节点的索引
let oldEnd = oldChildren.length - 1
// 指向新 children 最后一个节点的索引
let newEnd = newChildren.length - 1
oldVNode = oldChildren[oldEnd]
newVNode = newChildren[newEnd]
// while 循环向前遍历,直到遇到拥有不同 key 值的节点为止
while (oldVNode.key === newVNode.key) {
// 调用 patch 函数更新 ...
oldVNode = oldChildren[--oldEnd]
newVNode = newChildren[--newEnd]
}// 指向旧 children 最后一个节点的索引
let oldEnd = oldChildren.length - 1
// 指向新 children 最后一个节点的索引
let newEnd = newChildren.length - 1
oldVNode = oldChildren[oldEnd]
newVNode = newChildren[newEnd]
// while 循环向前遍历,直到遇到拥有不同 key 值的节点为止
while (oldVNode.key === newVNode.key) {
// 调用 patch 函数更新 ...
oldVNode = oldChildren[--oldEnd]
newVNode = newChildren[--newEnd]
}前缀结点和后缀结点处理完后的状态
j: 1
oldEnd: 0
newEnd: 1j: 1
oldEnd: 0
newEnd: 1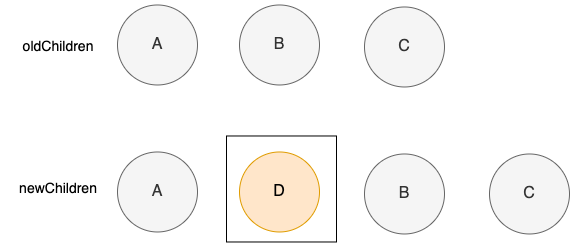
我们发现 j > oldEnd 并且 j <= newEnd,这说明当新旧 children 中相同的前缀和后缀被更新之后,旧 children 中的节点已经被更新完毕了,而新 children 中仍然有剩余节点,通过上图可以发现,新 children 中的 D 节点,就是这个剩余的节点。实际上新 children 中位于 j 到 newEnd 之间的所有节点都应该是新插入的节点,此时,应当将 [j, newEnd]区间之间的所有结点插入。
代码实现:
// 满足条件,则说明从 j -> newEnd 之间的节点应作为新节点插入
if (j > oldEnd && j <= newEnd) {
// 所有新节点应该插入到位于 nextPos 位置的节点的前面
const nextPos = newEnd + 1
const refNode = nextPos < newChildren.length ? newChildren[nextPos].el : null
// 采用 while 循环,将 [j, newEnd] 范围内的结点依次插入
while (j <= newEnd) {
mount(newChildren[j++], container, false, refNode)
}
}// 满足条件,则说明从 j -> newEnd 之间的节点应作为新节点插入
if (j > oldEnd && j <= newEnd) {
// 所有新节点应该插入到位于 nextPos 位置的节点的前面
const nextPos = newEnd + 1
const refNode = nextPos < newChildren.length ? newChildren[nextPos].el : null
// 采用 while 循环,将 [j, newEnd] 范围内的结点依次插入
while (j <= newEnd) {
mount(newChildren[j++], container, false, refNode)
}
}再看下面的这种情况
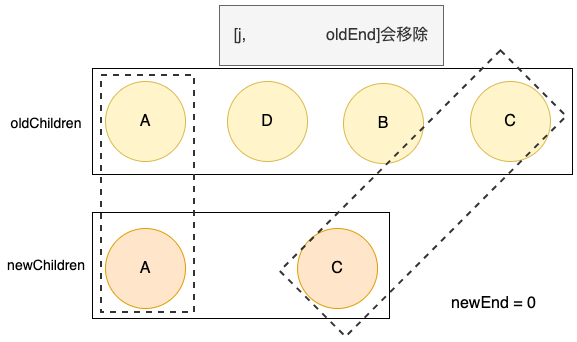
经过处理掉前后缀相同的结点后,此时
j = 1
oldEnd = 2
newEnd = 0j = 1
oldEnd = 2
newEnd = 0需要将就列表中 [j, oldEnd]之间的结点全部移除掉。代码实现:
else if (j > newEnd) {
// j -> oldEnd 之间的节点应该被移除
while (j <= oldEnd) {
container.removeChild(oldChildren[j++].el)
}
} else if (j > newEnd) {
// j -> oldEnd 之间的节点应该被移除
while (j <= oldEnd) {
container.removeChild(oldChildren[j++].el)
}
}移动结点的情况
上面的两种情况,一是新列表有多余的结点需要插入,另一种情况是旧列表中有多余的结点需要删除,均不涉及结点移动的情况。我们看下面的情况:
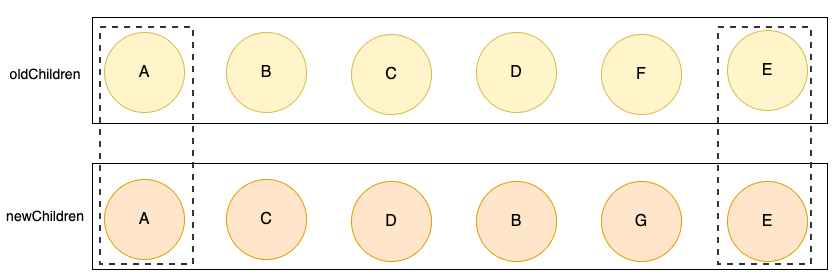
去除掉前后相同的结点A和E后,新旧列表分别剩余四个结点,且存在可复用的结点,此时就涉及结点的移动了。
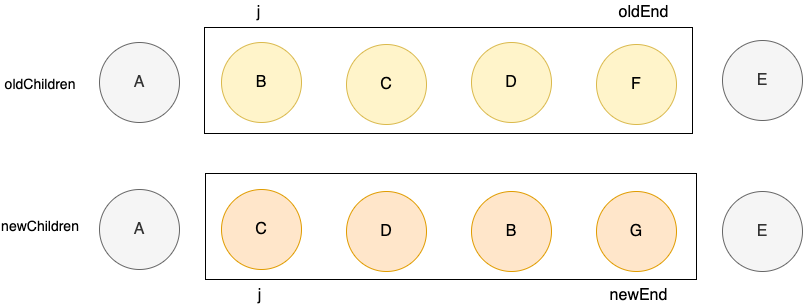
此时,各个标识位
j = 1;
newEnd = 4;
oldEnd = 4;j = 1;
newEnd = 4;
oldEnd = 4;不满足上面的条件分支了,需要增加else分支逻辑
// 满足条件,则说明从 j -> newEnd 之间的节点应作为新节点插入
if (j > oldEnd && j <= newEnd) {
// j -> newEnd 之间的节点应该被添加
// 省略...
} else if (j > newEnd) {
// j -> oldEnd 之间的节点应该被移除
// 省略...
} else {
// 这里处理结点移动的case
}// 满足条件,则说明从 j -> newEnd 之间的节点应作为新节点插入
if (j > oldEnd && j <= newEnd) {
// j -> newEnd 之间的节点应该被添加
// 省略...
} else if (j > newEnd) {
// j -> oldEnd 之间的节点应该被移除
// 省略...
} else {
// 这里处理结点移动的case
}我们构造一个 source 数组,里面存放新结点列表中的结点在旧列表中的位置。
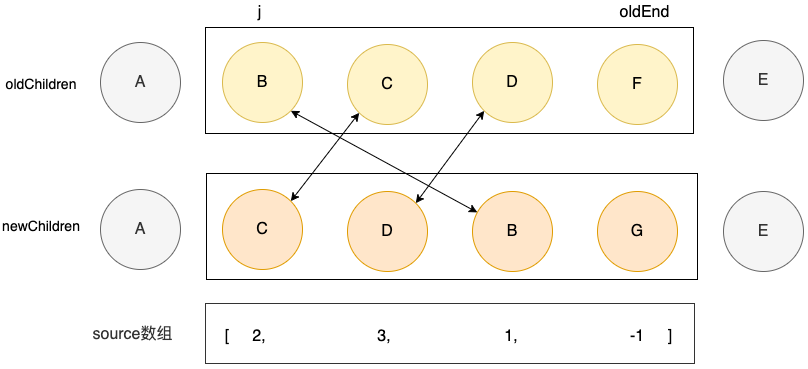
用两层 for 循环来实现:
const oldStart = j
const newStart = j
// 遍历旧 children
for (let i = oldStart; i <= oldEnd; i++) {
const oldVNode = oldChildren[i]
// 遍历新 children
for (let k = newStart; k <= newEnd; k++) {
const newVNode = newChildren[k]
// 找到拥有相同 key 值的可复用节点
if (oldVNode.key === newVNode.key) {
// 更新 source 数组
source[k - newStart] = i
}
}
}const oldStart = j
const newStart = j
// 遍历旧 children
for (let i = oldStart; i <= oldEnd; i++) {
const oldVNode = oldChildren[i]
// 遍历新 children
for (let k = newStart; k <= newEnd; k++) {
const newVNode = newChildren[k]
// 找到拥有相同 key 值的可复用节点
if (oldVNode.key === newVNode.key) {
// 更新 source 数组
source[k - newStart] = i
}
}
}如何判断是否需要移动节点呢?我们定义一个 moved类型的变量来标识,同时定义一个pos位置变量,k在遍历新列表的结点中,一旦发现后来遇到索引比之前遇到的索引要小,即 k < pos,则说明需要移动操作,这时更新变量 moved 的值为 true。
const oldStart = j
const newStart = j
// 遍历旧 children
let moved = false;
for (let i = oldStart; i <= oldEnd; i++) {
const oldVNode = oldChildren[i]
// 遍历新 children
for (let k = newStart; k <= newEnd; k++) {
const newVNode = newChildren[k]
// 找到拥有相同 key 值的可复用节点
if (oldVNode.key === newVNode.key) {
// 更新 source 数组
source[k - newStart] = i
}
if (k < pos) {
// 在新列表中的位置太小了,所以得移动
moved = true;
} else {
pos = k; // pos 始终维持一个最大的索引位置
}
}
}const oldStart = j
const newStart = j
// 遍历旧 children
let moved = false;
for (let i = oldStart; i <= oldEnd; i++) {
const oldVNode = oldChildren[i]
// 遍历新 children
for (let k = newStart; k <= newEnd; k++) {
const newVNode = newChildren[k]
// 找到拥有相同 key 值的可复用节点
if (oldVNode.key === newVNode.key) {
// 更新 source 数组
source[k - newStart] = i
}
if (k < pos) {
// 在新列表中的位置太小了,所以得移动
moved = true;
} else {
pos = k; // pos 始终维持一个最大的索引位置
}
}
}两层的for循环时间复杂度是O(n^2),这里我引入一个map变量将时间复杂度降为 O(n)
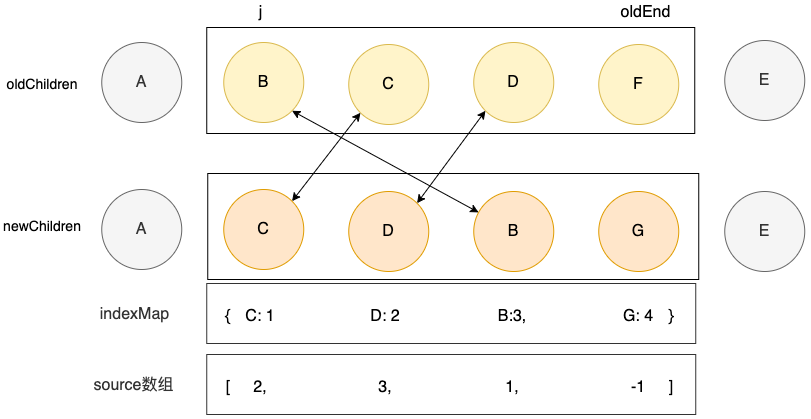
更新一下代码实现:
const oldStart = j
const newStart = j
let moved = false
let pos = 0
// 构建索引表
const keyIndex = {}
for(let i = newStart; i <= nextEnd; i++) {
keyIndex[newChildren[i].key] = i
}
// 遍历旧 children 的剩余未处理节点
for(let i = oldStart; i <= oldEnd; i++) {
oldVNode = oldChildren[i]
// 通过索引表快速找到新 children 中具有相同 key 的节点的位置
const k = keyIndex[oldVNode.key]
if (typeof k !== 'undefined') {
newVNode = newChildren[k]
// 更新 source 数组
source[k - newStart] = i
// 判断是否需要移动
if (k < pos) {
moved = true
// 移动结点...
} else {
pos = k
}
} else {
// 说明该结点在 的列表中不存在,应该移除掉
container.removeChild(oldVNode.el)
}
}const oldStart = j
const newStart = j
let moved = false
let pos = 0
// 构建索引表
const keyIndex = {}
for(let i = newStart; i <= nextEnd; i++) {
keyIndex[newChildren[i].key] = i
}
// 遍历旧 children 的剩余未处理节点
for(let i = oldStart; i <= oldEnd; i++) {
oldVNode = oldChildren[i]
// 通过索引表快速找到新 children 中具有相同 key 的节点的位置
const k = keyIndex[oldVNode.key]
if (typeof k !== 'undefined') {
newVNode = newChildren[k]
// 更新 source 数组
source[k - newStart] = i
// 判断是否需要移动
if (k < pos) {
moved = true
// 移动结点...
} else {
pos = k
}
} else {
// 说明该结点在 的列表中不存在,应该移除掉
container.removeChild(oldVNode.el)
}
}移动结点的方式
上面我们通过变量 moved知道哪些情况下需要移动结点,具体的移动逻辑改如何实现呢?
首先根据 source 数组计算一个最长递增子序列(Longest increasing subsequence)
if (moved) {
// 计算最长递增子序列
const seq = lis(sources) // [ 0, 1 ]
}if (moved) {
// 计算最长递增子序列
const seq = lis(sources) // [ 0, 1 ]
}这个 seq 就表示 新 children 中不需要移动的结点
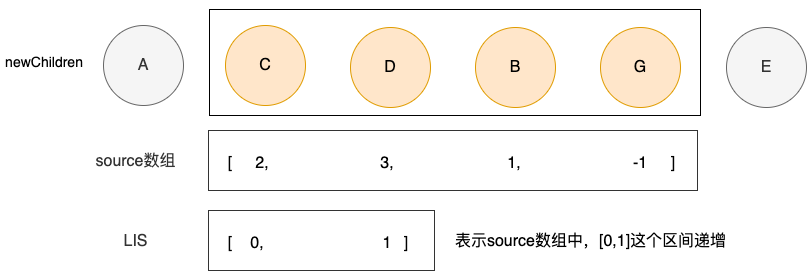
最长递增子序列是 [ 0, 1 ] 这告诉我们:新 children 的剩余未处理节点中,位于位置 0 和位置 1 的节点的先后关系与他们在旧 children 中的先后关系相同
因此,只有结点B 和结点G 可能会被移动,又因为结点G对应 source 数组 中的位置为 -1,说明G结点应该是一个新结点,需要被插入。 这样就只剩下 结点B需要被移动了。具体的执行过程:
i, j分别指向newChildren的最后一个位置以及递增序列的最后一个位置,从后往前(从右向左)依次比较。
if (moved) {
const seq = lis(source)
// j 指向最长递增子序列的最后一个值
let j = seq.length - 1
// 从后向前遍历新 children 中的剩余未处理节点
for (let i = nextLeft - 1; i >= 0; i--) {
if (i !== seq[j]) {
// 说明该节点需要移动
} else {
// 当 i === seq[j] 时,说明该位置的节点不需要移动
// 并让 j 指向下一个位置
j--
}
}
}if (moved) {
const seq = lis(source)
// j 指向最长递增子序列的最后一个值
let j = seq.length - 1
// 从后向前遍历新 children 中的剩余未处理节点
for (let i = nextLeft - 1; i >= 0; i--) {
if (i !== seq[j]) {
// 说明该节点需要移动
} else {
// 当 i === seq[j] 时,说明该位置的节点不需要移动
// 并让 j 指向下一个位置
j--
}
}
}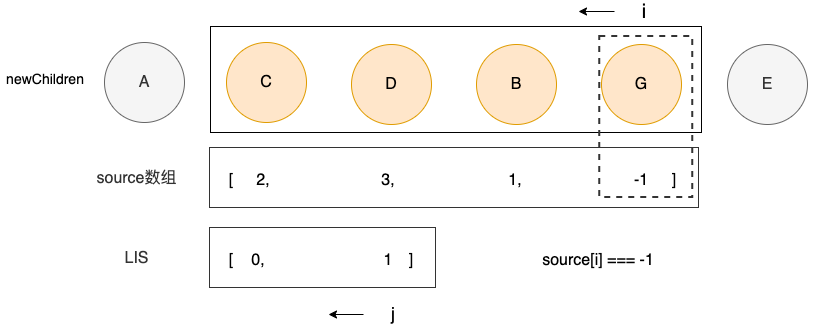
source[i] = -1,说明此时处理的结点G是一个新结点,需要挂载。
if (source[i] === -1) {
// 作为全新的节点挂载
// 该节点在新 children 中的真实位置索引
const pos = i + nextStart
const nextVNode = newChildren[pos]
// 该节点下一个节点的位置索引
const nextPos = pos + 1
// 挂载
mount(nextVNode, container, false, nextPos)
}if (source[i] === -1) {
// 作为全新的节点挂载
// 该节点在新 children 中的真实位置索引
const pos = i + nextStart
const nextVNode = newChildren[pos]
// 该节点下一个节点的位置索引
const nextPos = pos + 1
// 挂载
mount(nextVNode, container, false, nextPos)
}之后,i的位置向左移动一位,j保持不变,开始比较下一个结点B
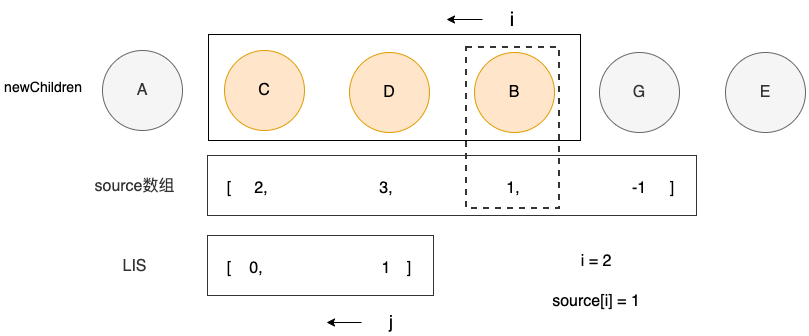
i = 2, 且 source[i] != -1, i != seq[j] ,说明此时处理的结点B既不是一个新结点,也不满足等于序列中的最大值的要求,需要移动。
else if (i !== seq[j]) {
// 说明该节点需要移动
// 该节点在新 children 中的真实位置索引
const pos = i + nextStart
const nextVNode = newChildren[pos]
// 该节点下一个节点的位置索引
const nextPos = pos + 1
// 移动
container.insertBefore(nextVNode.el, nextPos);
}else if (i !== seq[j]) {
// 说明该节点需要移动
// 该节点在新 children 中的真实位置索引
const pos = i + nextStart
const nextVNode = newChildren[pos]
// 该节点下一个节点的位置索引
const nextPos = pos + 1
// 移动
container.insertBefore(nextVNode.el, nextPos);
}之后,i的位置向左移动一位,j继续保持不变,开始比较下一个结点D
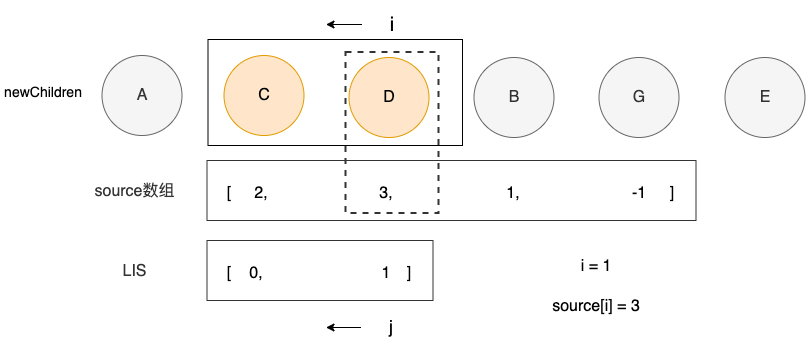
可以看到这时,满足 i = seq[j] = 1,说明结点D不需要移动。
之后,i的位置向左移动一位,j的位置也要左移一位,开始比较下一个结点C
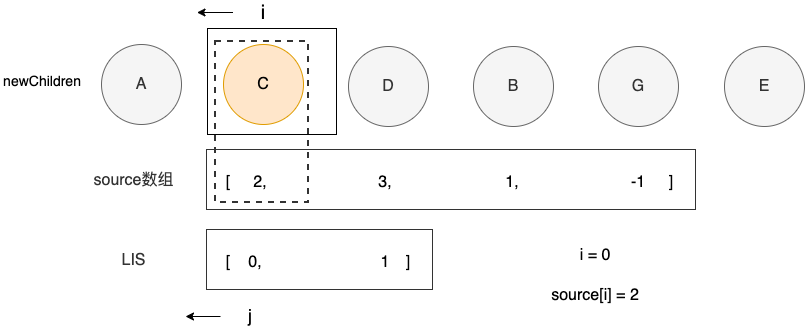
此时,结点C 在的索引i = seq[j]满足不需要移动的条件,至此所有的结点就都处理完成了。
最长递增子序列
在上面的求解 source 数组的最长递增子序列中
if (moved) {
// 计算最长递增子序列
const seq = lis(sources) // [ 0, 1 ]
}if (moved) {
// 计算最长递增子序列
const seq = lis(sources) // [ 0, 1 ]
}提到了 lis方法(其实是Longest increasing subsequence的缩写),这个方法的含义表示在一个集合中找到最大的子序列。 比如下面举几个例子:
- [2, 3, 5, 0, 1, 8, 9] 最大子序列为 [2, 3, 5, 8, 9]
- [3, 10, 6, 7, 9, 1] 最大子序列为 [3, 6, 7, 9]
- [10, 9, 2, 5, 3, 7, 101, 18] 最大子序列为 [2, 3, 7, 101]
该算法,也是leetcode 上的的高频题目,采用动态规划的思想求解,感兴趣可以查看具体的实现过程。